
یکی از دستاوردهای مهم نرمافزار آزاد، شکلگیری جامعهای پویا از کاربران است؛ جامعهای که در آن پرسش و پاسخ، انتقال تجربه و حل مسئله بهصورت جمعی انجام میشود.
لیبرهآفیس نمونهای روشن از همین فرهنگ مشارکتی است؛ جایی که تجربهٔ یک کاربر میتواند راهگشای مشکل کاربران دیگر باشد.
برای مثال این یادداشت آموزشی در اصل از یک پرسش ساده شروع شد. مسئلهای که یکی از کاربران لیبرهآفیس مطرح کرد و من گمان میکردم راهحلی برایش وجود ندارد، اما داشت و در در دل گفتوگوها با پیگیری همان کاربر پیدا شد.
از شما چهپنهان بسیاری دیگر از نوشتههای این وبلاگ از همین جنساند و از دل پرسشها، تجربهها و گفتوگوهایی که در مسیر استفاده از لیبرهآفیس پیش آمدهاند به یادداشتهای آموزشی تبدیل شدهاند.
ممکن است گفته شود که چنین پرسشوپاسخهایی دربارهٔ نرمافزارهای انحصاری (مانند مایکروسافتآفیس) هم وجود دارد و انجمنها و وبسایتهای متعددی برای طرح سؤال دربارهٔ آنها فعال هستند.
ظاهراً درست به نظر میرسد، اما تفاوت اصلی در «ماهیت» و «پایداری» این تبادل دانش نهفته است.
در نرمافزارهای آزاد، پرسش و پاسخ صرفاً راهکاری موقت برای استفادهٔ بهتر از یک محصول نیست، بلکه بخشی از فرآیند جمعیِ بهبود نرمافزار محسوب میشود. پاسخها محدود به چارچوبهای بستهٔ شرکت سازنده نیستند و دانش تولیدشده میتواند مستقیماً به مستندات رسمی، راهنماها و حتی به خودِ کد منبع منتقل شود.
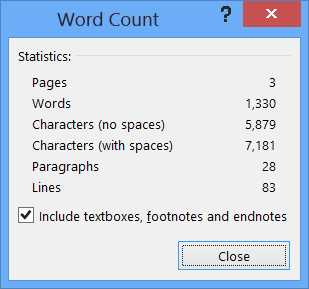 همانطور که در تصویر مشخص است، یک چکباکس ساده در پایین پنجره وجود دارد با عنوان: شامل کردن کادرهای متنی، پانویسها و یادداشتهای پایانی.
همانطور که در تصویر مشخص است، یک چکباکس ساده در پایین پنجره وجود دارد با عنوان: شامل کردن کادرهای متنی، پانویسها و یادداشتهای پایانی.

 اما چطور باید در لیبرهآفیس از این قابلیت استفاده کرد؟
اما چطور باید در لیبرهآفیس از این قابلیت استفاده کرد؟




