
در نگارش مقالات علمی، پایاننامهها یا متونی که دارای محدودیت تعداد کلمات هستند، نویسندگان اغلب با یک چالش رایج مواجه میشوند: آیا محتوای پانویسها، پینوشتها و کادرهای متنی باید در شمارش کلمات لحاظ شوند یا خیر؟
ابزار شمارش کلمات لیبرهآفیس متأسفانه انعطافپذیری لازم را ندارد و تمامی متون موجود در سند را محاسبه میکند، از جمله:
- توضیحات اضافی در پانویسها
- ارجاعات در پینوشتها یا یادداشتهای پایان
- ینوشتههای داخل کادرهای متنی (که ممکن است نمودار یا توضیح تصویر باشند)
این مسئله برای نویسندهای که با محدودیت کلمات مواجه است، دشوار و آزاردهنده بوده و او را مجبور به محاسبهٔ دستی یا روشهای زمانبر دیگر میکند.
چه باید کرد؟ 🤔
یک راهحل ساده و کاربردی برای این مشکل وجود دارد که قبلاً در واژهپرداز مایکروسافت ورد پیادهسازی شده است.
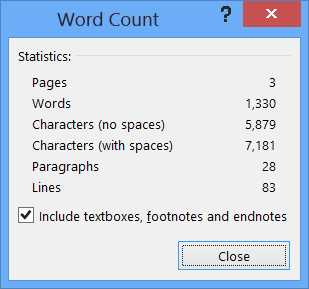 همانطور که در تصویر مشخص است، یک چکباکس ساده در پایین پنجره وجود دارد با عنوان: شامل کردن کادرهای متنی، پانویسها و یادداشتهای پایانی.
همانطور که در تصویر مشخص است، یک چکباکس ساده در پایین پنجره وجود دارد با عنوان: شامل کردن کادرهای متنی، پانویسها و یادداشتهای پایانی.
اگر کاربر بخواهد تعداد کلمات بدون احتساب پانویسها، پینوشتها و کادرها را بداند، کافی است تیک این گزینه را بردارد. بلافاصله آمارهای نمایشدادهشده (تعداد کلمات، نویسهها و…) بهروزرسانی شده و اعداد جدید نشان داده میشود. در مایکروسافت ورد، این تنظیم حتی بر شمارش کلماتی که در نوار وضعیت (در پایین صفحه) نمایش داده میشود نیز تأثیر میگذارد. به این معنا که با برداشتن تیک این گزینه در پنجرهٔ گفتگو، عدد داخل نوار وضعیت نیز بهطور خودکار تغییر کرده و تعداد کلمات بدون احتساب پانویسها را نشان میدهد. این یکپارچگی، کار با برنامه را آسانتر میسازد.
اضافه شدن چنین قابیتی قبلاً از لیبرهآفیس هم درخواست شده (اینجا) اما متأسفانه با اینکه ده سال هم از آن گذشته، هنوز پیادهسازی نشده است!
افزودن این چکباکس نه تنها یک نیاز واقعی کاربران را برآورده میکند، بلکه با الگوبرداری از یک راهحل موفق و ساده در نرمافزاری انحصاری، میتواند قابلیتهای یک نرمافزار آزاد (لیبرهآفیس) را برای طیف گستردهتری از کاربران، از جمله نویسندگان حرفهای و دانشگاهیان، بهبود بخشد.

 اما چطور باید در لیبرهآفیس از این قابلیت استفاده کرد؟
اما چطور باید در لیبرهآفیس از این قابلیت استفاده کرد؟





